

A reproducible benchmark suite for characterizing PyTorch Distributed Data Parallel (DDP) training performance on NVIDIA GPU clusters. Built for pre-production validation of large-scale HPC infrastructure, and generalized for broader use on any Slurm-based system or cloud instance.

What It Does #
The benchmark runs training on synthetic on-device data to isolate GPU compute and NCCL communication from storage I/O. It measures two complementary scaling modes:
Weak scaling keeps per-GPU batch size fixed while adding GPUs. This answers whether each GPU stays productive as the system grows. Throughput per GPU should stay flat; a drop reveals communication overhead.
Strong scaling keeps the global batch fixed while adding GPUs. This answers how much faster the same workload runs with more resources, expressed as speedup and parallel efficiency relative to a single-GPU baseline.
Results are collected as JSON per run and aggregated into tables and plots. GPU activity is sampled during measurement via nvidia-smi, and low-utilization configurations are flagged automatically.
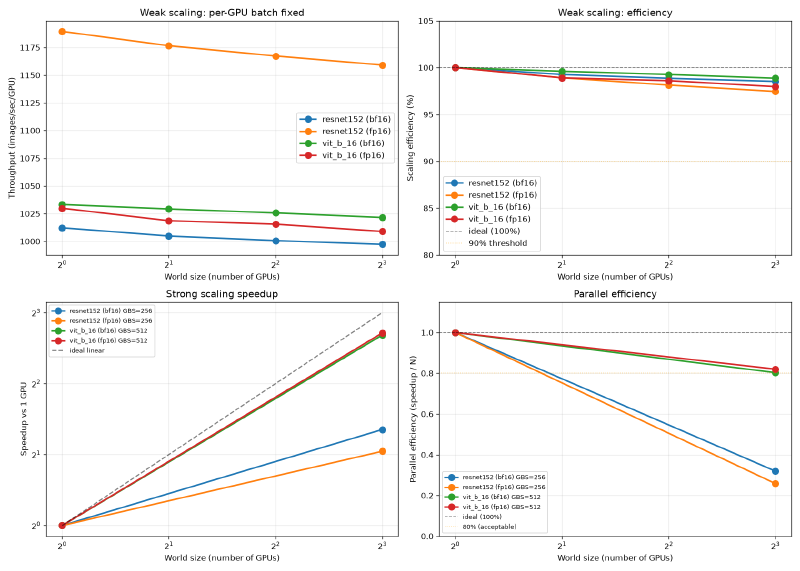
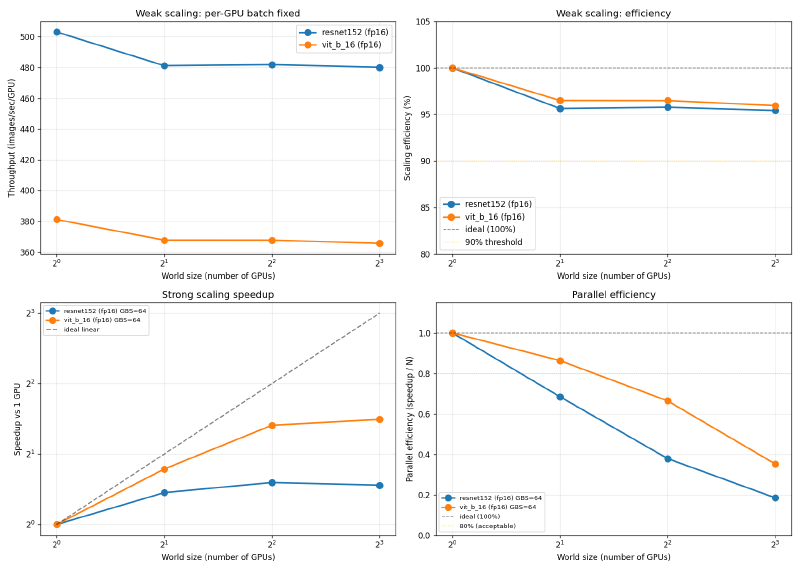
Results: V100 vs A100 #
Full analysis is in the blog post.
Weak scaling efficiency (fp16, 1 to 8 GPUs):
| GPU | Model | Per-GPU BS | 1 GPU img/s | 8 GPU efficiency |
|---|---|---|---|---|
| V100 SXM2 16GB | ResNet-152 | 128 | 503 | 95.4% |
| V100 SXM2 16GB | ViT-B/16 | 128 | 381 | 95.9% |
| A100 SXM4 80GB | ResNet-152 | 512 | 1190 | 97.4% |
| A100 SXM4 80GB | ViT-B/16 | 1024 | 1030 | 98.0% |
Generation comparison (fp16, each GPU at its max batch size):
| Model | V100 img/s/GPU | A100 img/s/GPU | Ratio |
|---|---|---|---|
| ResNet-152 | 503 | 1190 | 2.37x |
| ViT-B/16 | 381 | 1030 | 2.70x |
-
A100 SXM4 80GB
-
V100 SXM2 16GB
Why It Was Built #
Statewide AI research infrastructure serving hundreds of researchers needs to be validated before opening to users. This benchmark was developed to stress-test GPU compute and inter-node communication on B200 and RTX Pro 6000 Blackwell hardware before cluster launch, and to produce numbers that can be reported to stakeholders in a reproducible way.
Technical Details #
- Language: Python 3.10+, Bash
- Framework: PyTorch with
torch.distributed/ NCCL - Scheduler: Slurm (torchrun + srun for multi-node) or direct instance execution
- Models: ResNet-152, ViT-B/16, ResNet-50, ResNet-101
- Precision: fp16 and bf16
- Utilities:
find_max_bs.pyfor per-GPU batch size calibration - Outputs: per-run JSON, terminal tables, matplotlib PNG plots