

노트북을 중간 다리로 쓰는 걸 멈추세요.
첫 번째 HPC Special Topics 포스트에 온 걸 환영합니다. 특정 주제를 깊게 파고드는 독립 포스트 시리즈입니다.
데이터 전송 포스트에서 scp와 rsync로 파일을 옮기는 방법을 배웠습니다. 노트북에서 클러스터로 전송할 때는 잘 됩니다. 그런데 클라우드 스토리지는요?
상황을 상상해봅니다. 교수님이 Google Drive에 200GB 데이터셋을 공유해줬습니다. 적절한 도구 없이는 노트북에 먼저 내려받고 (운 좋으면 2시간), 다시 클러스터에 scp로 올려야 합니다 (또 2시간). 파일 전송만 4시간입니다.
노트북을 완전히 건너뛰고 Google Drive에서 /scratch 디렉토리로 명령어 하나로 직접 다운받을 수 있다면요?
그게 바로 Rclone이 하는 일입니다.
기본 사용법을 넘어서, 경험 많은 HPC 엔지니어들이 자주 논하는 최적화 기법도 알아볼 겁니다. 병렬 스레드가 전송 속도를 극적으로 바꿀 수 있는 경우와 그렇지 않은 경우입니다.
1. 왜 Rclone을 쓸까요? #
Rclone은 클라우드 스토리지 파일을 관리하는 커맨드라인 프로그램입니다. rsync라고 생각하되 클라우드용입니다. Google Drive, Dropbox, OneDrive, Box, AWS S3, SFTP까지 70개 이상의 클라우드 스토리지 제공업체를 지원합니다.
HPC에서 이게 왜 중요할까요?
직접 전송: Google Drive에서 클러스터의 /scratch 공간으로 노트북을 거치지 않고 바로 데이터를 옮겨요. 내려받고 다시 올리고하는 사이클이 없어져요.
병렬화: 파일 하나를 단일 스트림으로 보내는 scp와 달리, Rclone은 여러 파일을 동시에 전송할 수 있습니다. 여기서 흥미로운 부분이 생겨요 (섹션4에서 자세히 다뤄요).
안정성: Rclone은 재시도, 체크섬, 중단된 전송을 자동으로 처리합니다. 99%에서 연결이 끊겨도 이어서 진행합니다. 클라우드 스토리지용 rsync -P입니다.
다양성: 도구 하나로 백엔드 70개 이상. 협업자가 Google Drive에서 데이터를 공유하든, 기관이 Box를 쓰든, 파이프라인이 S3에 결과를 저장하든, 같은 인터페이스로 모두 처리합니다.

2. HPC에서 Rclone 설정하기 #
중요: 많은 HPC 클러스터에서 로그인 노드에서 대용량 데이터 전송을 금지합니다. 클러스터 정책을 먼저 확인하세요. 대용량 전송이 제한된다면 컴퓨트 작업 안에서 Rclone을 실행하세요.
$ srun --pty bash $ module load rclone $ rclone copy ...
1단계: Rclone 로드 #
많은 HPC 클러스터에 Rclone이 모듈로 이미 설치되어 있습니다.
$ module avail rclone
$ module load rclone모듈이 없다면 홈 디렉토리에 직접 설치할 수 있습니다.
# 다운로드 및 압축 해제
$ curl -O https://downloads.rclone.org/rclone-current-linux-amd64.zip
$ unzip rclone-current-linux-amd64.zip
# 바이너리를 로컬 bin으로 이동
$ mkdir -p ~/bin
$ cp rclone-*/rclone ~/bin/
# 확인
$ ~/bin/rclone version참고: 직접 설치했다면
~/bin이$PATH에 있어야 합니다. 아니면~/bin/rclone으로 전체 경로를 씁니다.
2단계: Google Drive 연결 (헤드리스 인증) #
대부분의 초보자가 막히는 부분입니다. HPC 클러스터에는 웹 브라우저가 없으니 헤드리스 설정으로 인증해야 합니다.
rclone config를 실행하고 새 원격지를 위해n을 선택합니다.- 기억하기 쉬운 이름을 붙여요 (예:
gdrive). - Google Drive에 해당하는 번호를 선택합니다.
- 나머지 프롬프트(클라이언트 ID, 시크릿, 스코프, 루트 폴더 ID, 서비스 계정, 고급 설정)는 모두 Enter를 눌러 기본값을 쓰세요.
- “auto config를 사용할까요?” 라는 질문에
n을 선택합니다. 브라우저 없는 원격 서버에서는 이게 중요합니다. - Rclone이 URL을 알려줍니다. 이 URL을 로컬 노트북 브라우저에 복사해서 붙여넣습니다.
- Google 계정에 로그인하고 Rclone을 승인한 뒤 인증 코드를 HPC 터미널에 복사합니다.
- Team Drive 관련 질문에는
n을 선택합니다. (Team Drive를 쓰지 않는다면) y로 저장을 확인합니다.
(Rclone overview를 확인해 자세한 설명과 다른 클라우드 서비스를 사용하는 방법을 알아보세요.)
$ rclone config
# 위 단계를 따라하세요
# ...
# 연결 확인
$ rclone lsd gdrive:
# Google Drive 폴더 목록이 보여야 합니다폴더가 보인다면 연결된 겁니다.
팁: 같은 과정이 Dropbox, OneDrive, Box에도 적용됩니다. 3단계에서 다른 제공업체 번호를 선택하면 됩니다. 제공업체마다 인증 단계가 약간 다르지만 Rclone이 대화식으로 안내해줍니다.
3. 핵심 명령어 #
최적화로 들어가기 전에 일상적으로 쓸 명령어들을 먼저 살펴봅니다.
목록 조회 및 탐색
# 클라우드의 최상위 디렉토리 목록
$ rclone lsd gdrive:
# 특정 폴더의 파일 목록
$ rclone ls gdrive:my_project/data
# 디렉토리 트리 표시 (탐색에 유용합니다)
$ rclone tree gdrive:my_project --max-depth 2
# 저장 공간 사용량 확인
$ rclone about gdrive:데이터 복사
# 클라우드 -> 클러스터 (가장 흔한 사용 사례)
$ rclone copy gdrive:my_data ~/scratch/my_data -P
# -P: 실시간 진행 상황, 속도, 예상 완료 시간을 보여줍니다.
# 클러스터 -> 클라우드 (결과 백업)
$ rclone copy ~/scratch/results gdrive:results -Pcopy vs. sync 차이 알기
# copy: 새 파일만 추가합니다. 대상에서 아무것도 삭제하지 않아요.
$ rclone copy gdrive:data ~/scratch/data -P
# sync: 대상을 소스와 동일하게 만들어요. 소스에 없는
# 파일을 대상에서 삭제합니다. 주의해서 사용하세요!
$ rclone sync gdrive:data ~/scratch/data -P경고:
rclone sync는 소스에 없는 파일을 대상에서 삭제합니다. 실행 전에 명령어를 꼭 다시 확인하세요. 확실하지 않다면copy를 쓰세요.
여기까지가 Rclone을 일상 도구로 쓰기 위해 필요한 모든 것입니다. 다음 섹션에서는 어떻게 더 빠르게 만들 수 있는지 알아봅니다.
4. 최적화 과제: 스레드 vs. 대역폭 #
실제 WAN 시나리오에서는 단일 TCP 스트림이 지연 시간, TCP 윈도우 제한, 제공업체 측 쓰로틀링 때문에 가용 대역폭을 완전히 활용하지 못하는 경우가 많습니다. 해결책은 뭘까요? 스트림을 더 열면 됩니다.
Rclone에는 이를 위한 핵심 플래그가 있습니다.
--transfers=N # 동시에 전송할 파일 수 (기본값: 4)그럼 이런 의문이 생길 수 있습니다.
- 스레드를 늘리면 항상 빨라질까요?
- 수확 체감 지점이 있을까요?
- 업로드(전송)와 다운로드(수신)가 같은 방식으로 작동할까요?
실험 설계
- 환경: 4코어 HPC 컴퓨트 노드, 1Gbps 네트워크, 기본 Google Drive API(공유 클라이언트 ID)로 Rclone 사용.
- 시나리오 A: 단일 대용량 파일 5GB (압축 효과를 막기 위해
/dev/urandom으로 생성). - 시나리오 B: 소용량 파일 1,000개 (각 1MB, 동일하게 랜덤 데이터).
- 변수:
--transfers를 1, 4, 8, 16, 32로 설정. - 반복: 일관성 확인을 위해 조건당 3회 실행.
5. 벤치마크 결과 #
시나리오 A: 단일 대용량 파일 (5GB) #
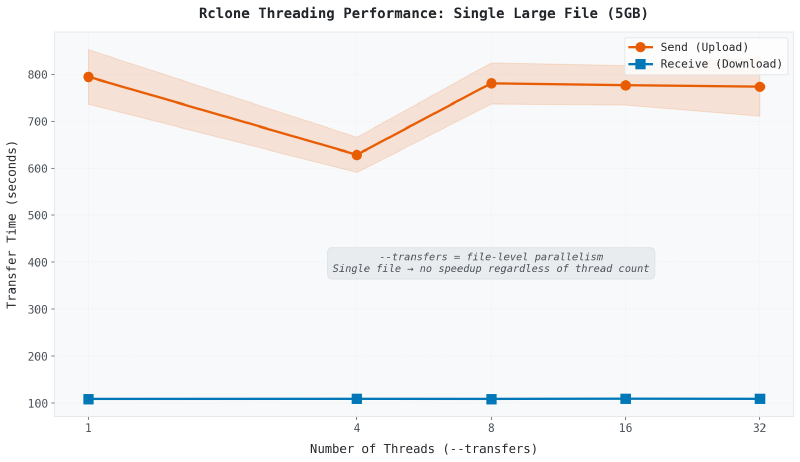
그래프가 평평합니다. --transfers를 1로 설정하든 32로 설정하든 전송 시간이 거의 변하지 않습니다.
왜일까요? --transfers는 파일 수준 병렬성을 제어하기 때문입니다. 동시에 전송할 파일 슬롯 수를 결정합니다. 파일이 하나뿐이라면 병렬화할 게 없습니다. 파일 하나, 스트림 하나, 스레드 수와 관계없이요.
흔한 오해가 있습니다. --transfers=16은 단일 파일을 16개 청크로 분할하지 않습니다. 16개의 별도 파일을 위한 16개의 슬롯을 여는 겁니다.
추가 참고: Rclone은 지원되는 백엔드에서 단일 대용량 파일의 청크 수준 병렬 다운로드를 위한
--multi-thread-streams를 제공합니다. 다운로드에서만 작동하고 제공업체에 따라 효과가 다릅니다. 대부분의 사용 사례에서는 여기서 다룬--transfers플래그가 맞습니다.
핵심: 대용량 단일 파일에서는
--transfers증가가 효과가 없습니다. 전송 속도는 네트워크 대역폭과 클라우드 제공업체의 스트림당 처리량이 결정합니다.
시나리오 B: 소용량 파일 (1,000 × 1MB) #
여기서 스레드의 진가가 나옵니다.
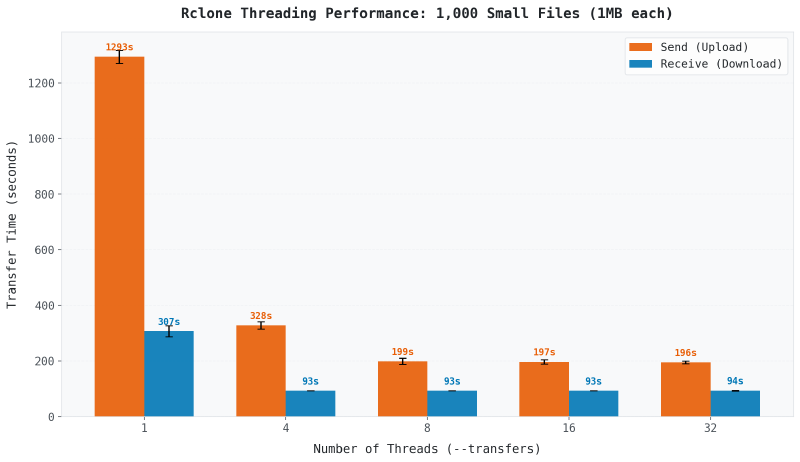
단일 스레드로 1,000개 파일을 업로드하는 데 1,293초 (약 21분)가 걸렸습니다. 8개 스레드에서는 199초 (약 3분)로 줄었습니다. 플래그 하나만 바꿨는데 6.5배 속도 향상입니다.
다운로드는 조금 다른 이야기입니다. 스레드 1개에서 307초였고 4개에서 93초 (3.3배 향상)로 내려갔습니다. 4개 스레드를 넘어서는 다운로드 속도가 거의 변하지 않았습니다.
소용량 파일이 왜 스레드에 그렇게 민감할까요? 각 파일 전송에는 API 호출, 메타데이터 확인, 체크섬 검증, 연결 오버헤드가 수반됩니다. 단일 스레드에서는 다음 파일을 시작하기 전에 이 모든 게 완료되길 기다려야 합니다. 여러 스레드는 전송을 겹치게 해서 파일당 지연 시간을 숨깁니다. 그래서 속도 향상이 극적인 겁니다.
6. 최적 지점 찾기 #
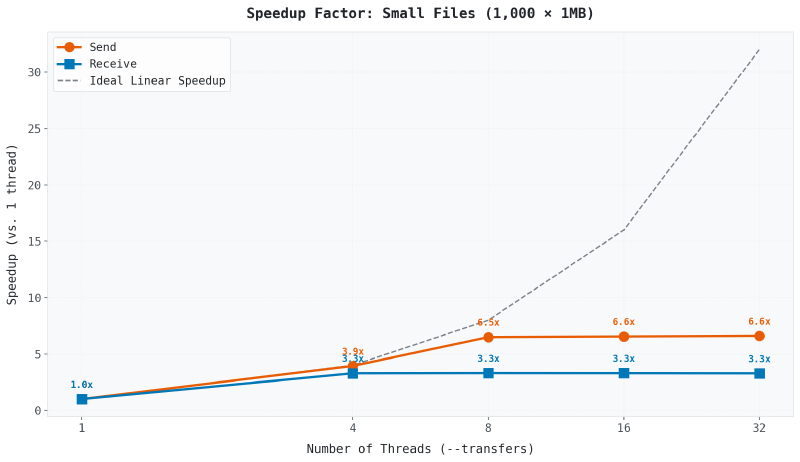
평탄화 효과 #
8개 스레드 이후에는 성능 향상이 사실상 멈추네요. 왜일까요?
API 속도 제한. Google Drive(대부분의 클라우드 제공업체)는 초당 API 요청 수를 제한합니다. 제공업체의 한도를 넘는 스레드를 추가하면 쓰로틀링과 재시도만 생겨요. 모든 Rclone 사용자가 공유하는 기본 API 클라이언트 ID를 쓸 때 특히 엄격합니다.
파워 유저 팁: 직접 Google API 클라이언트 ID를 만들면 API 할당량을 크게 늘릴 수 있고 최적 스레드 수가 더 높아질 수 있습니다. 자세한 내용은 Rclone Google Drive 문서를 참고하세요.
오버헤드. 동시 전송 32개를 관리하면 연결 설정, 체크섬 확인, 재시도 로직 자체에 오버헤드가 생깁니다. 이 모든 것이 리소스를 놓고 경쟁합니다.
전송 (업로드) vs. 수신 (다운로드) #
모든 조건에서 다운로드가 업로드보다 훨씬 빠르고 더 빨리 포화 상태에 도달합니다.
업로드할 때 클라우드 제공업체는 각 파일이 도착하는 대로 확인, 인덱싱, 저장해야 합니다. 다운로드할 때는 최적화된 CDN 인프라에서 파일을 제공하므로 파일당 처리 오버헤드가 적습니다. 이 비대칭성 때문에 전송 방향에 따라 최적 --transfers 값이 달라져요.
효율: 왜 8이 마법의 숫자인가 #
각 스레드가 속도 향상에 얼마나 효율적으로 기여하는지 측정할 수 있습니다.
$$ Efficiency = \frac{Speedup}{Number \: of \: Threads} \times 100\% $$
| 스레드 | 전송 속도 향상 | 효율 |
|---|---|---|
| 1 | 1.0x | 100% |
| 4 | 3.9x | 98% |
| 8 | 6.5x | 81% |
| 16 | 6.6x | 41% |
| 32 | 6.6x | 21% |
8개 스레드에서 81% 효율이 나옵니다. 각 스레드가 제 몫을 하고 있습니다. 32개 스레드에서는 21%로 떨어집니다. 리소스는 4배 더 쓰는데 속도 향상은 거의 없습니다.
이 특정 환경(1Gbps 네트워크, 기본 Google Drive API 클라이언트)에서는 8개 스레드가 최적 지점이었습니다. 네트워크 속도, 클라우드 제공업체, API 설정에 따라 최적 수가 달라질 수 있지만 찾는 방법은 같습니다. 테스트하고, 측정하고, 비교합니다.
참고: 이 수치는 기본 공유 API 클라이언트 ID를 쓰는 Google Drive에서 나온 것입니다. 클라우드 제공업체, 네트워크 속도, API 설정에 따라 결과가 달라질 수 있습니다. 방법론은 어디서나 적용 가능합니다.
7. 요약 & 권장사항 #
Rclone은 단순한 편의 도구가 아닙니다. 클라우드 스토리지와 클러스터 사이의 직접적인 파이프라인입니다.
핵심 정리:
- 노트북을 건너뛰세요. Rclone으로 클라우드와 클러스터 사이에 직접 전송하세요.
- 소용량 파일에는 스레드가 중요합니다. 스레드는 파일당 지연 시간 오버헤드를 숨겨요. 파일이 수천 개라면?
--transfers 8또는--transfers 16을 씁니다. - 단일 대용량 파일에는 스레드가 도움 안 됩니다.
--transfers는 파일 수준 병렬성이지 파일 분할이 아닙니다. - 업로드와 다운로드가 다르게 작동합니다. 다운로드가 더 빨리 포화됩니다. 방향에 따라 계획하세요.
- 과하게 하지 마세요. 스레드를 64로 설정하면 API 쓰로틀링이 걸려 오히려 느려져요.
- 가능하면 묶습니다. Rclone을 써도 소용량 파일 100,000개는 느립니다. 먼저
tar로 묶는 걸 고려하세요 (데이터 전송 포스트에서 다뤘습니다).
| 시나리오 | 권장 명령어 |
|---|---|
| 소용량 파일 다수 | rclone copy remote:path local:path --transfers 8 -P |
| 대용량 파일 소수 | rclone copy remote:path local:path -P |
| 디렉토리 동기화 | rclone sync remote:path local:path -P (주의해서 사용) |
| 전송 전 확인 | rclone lsd remote: 와 rclone about remote: |
다음은?
HPC 툴킷에 핵심 도구를 하나 더 추가했습니다. 다음 시리즈에서는 방향을 완전히 바꿀 겁니다. 클러스터를 사용하는 것에서 직접 만드는 것으로요. 하드웨어, 네트워킹, 그리고 부품 더미를 실제 HPC 시스템으로 만드는 방법을 다룰 겁니다.
다음 시리즈에서 만나요!
즐거운 컴퓨팅 되세요!